Key takeaways
- Citation accuracy depends heavily on how a platform collects data: UI scraping (real user interface) vs. API polling produces meaningfully different results, and most platforms don't tell you which method they use.
- Peec AI uses UI scraping to simulate real user interactions, which generally produces more accurate citation data than API-only approaches.
- Promptwatch tracks 10 AI models via real UI interfaces and adds crawler log data, giving you both citation accuracy and the technical context to understand why a page is or isn't being cited.
- Profound targets enterprise teams with strong analytics depth, but its higher price point and lack of content generation tools mean you still need other platforms to act on the data.
- Relixir is the newest entrant and focuses on automated content generation to close citation gaps, though its citation tracking depth is thinner than the other three.
Why citation accuracy actually matters
Most marketers treating AI visibility as a reporting exercise are asking the wrong question. "How often does our brand appear?" is less useful than "When our brand appears, is that citation data accurate enough to act on?"
If a platform shows you appearing in 60% of responses for a given prompt, but that number is pulled from API outputs rather than what real users actually see, you might be optimizing for a phantom metric. The gap between API responses and real user interface responses can be significant. AI models serve different answers depending on context, user history, conversation flow, and interface. An API call strips all of that away.
This is the core tension in the citation tracking space right now. Some platforms are fast and cheap because they poll APIs. Others are slower and more expensive because they simulate actual user sessions. The difference matters enormously if you're making content decisions based on the data.
Here's how the four main platforms stack up.
How each platform collects citation data
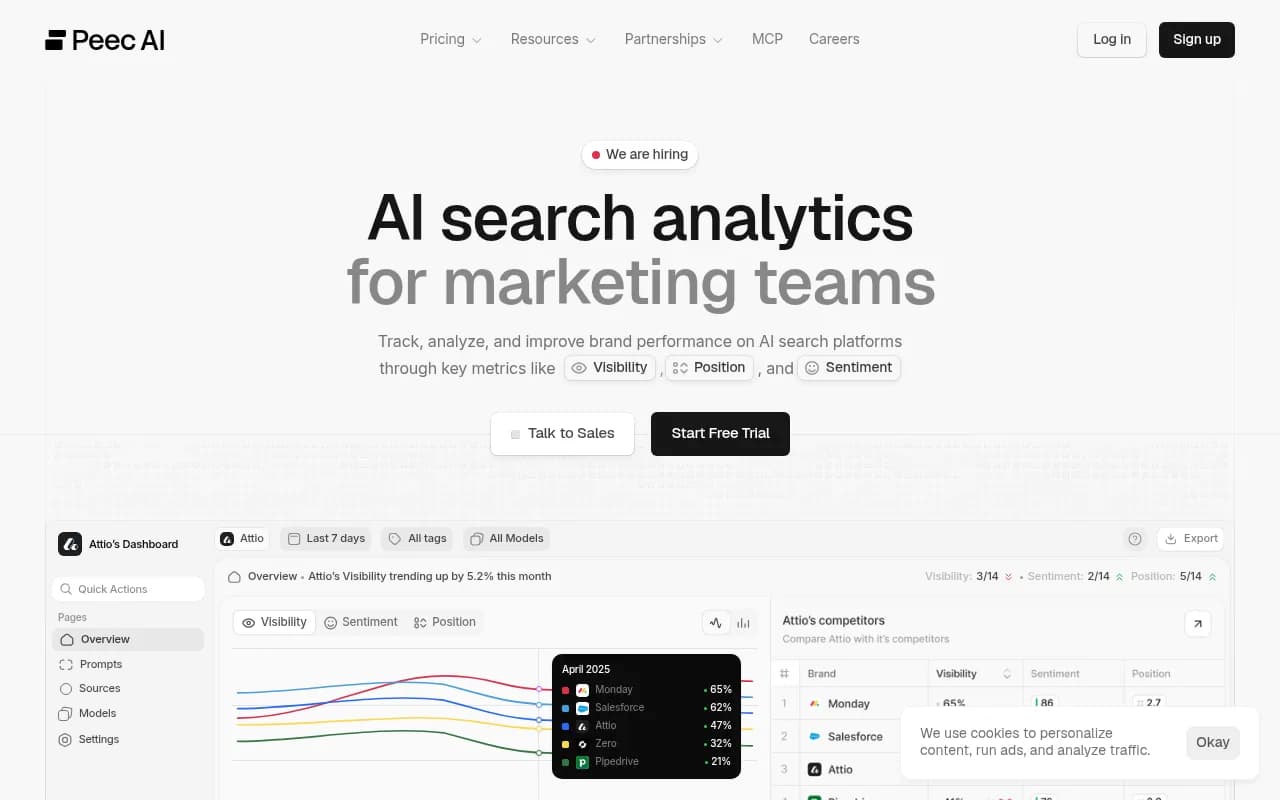
Peec AI
Peec AI built its tracking around UI scraping, meaning it simulates real user interactions with ChatGPT, Perplexity, and Google AI Overviews rather than hitting APIs directly. According to their own documentation, this approach captures what users actually see, not what the API returns in isolation.
The practical benefit: citation URLs and source panels in Peec's data reflect what appears in the actual interface. If ChatGPT's real-time browsing surfaces a different set of sources than its API would return, Peec captures the real version.
The limitation is coverage. On Starter and Pro plans, Peec tracks only three AI platforms. Enterprise unlocks broader coverage, but pricing isn't public at that tier. For teams that care about Gemini, Grok, Claude, or DeepSeek, Peec's lower plans leave significant blind spots.
Promptwatch
Promptwatch also tracks AI responses through real user interfaces rather than API polling, which puts it in the same accuracy tier as Peec for the data it collects. But it covers 10 AI models across all plans, not just three.
Where Promptwatch goes further is in the context around citations. Beyond showing which URLs appear in AI responses, it logs AI crawler activity directly. If ChatGPT's crawler visits your site, Promptwatch captures that event: which page was read, any errors encountered, how frequently the crawler returns, and whether a crawl eventually leads to a citation. That's a layer of data Peec doesn't offer.
For citation accuracy specifically, this matters because you can cross-reference what you see in the AI response with what the crawler actually accessed. If a page is being cited but the crawler last visited it six months ago, you know the citation is based on stale content. That's actionable in a way that a simple citation count isn't.
Profound
Profound sits at the enterprise end of the market. Its citation tracking is thorough and designed for teams that need to report AI visibility to stakeholders with confidence. The platform covers more AI models than Peec's lower tiers and includes strong competitive benchmarking.
The honest limitation: Profound is primarily an analytics and reporting platform. It gives you accurate citation data and good dashboards, but it doesn't help you close the gaps it identifies. There's no content generation, no content brief creation, no crawler log analysis. You get the diagnosis without the treatment.
For enterprise teams with dedicated content teams who just need reliable data to direct their work, that's fine. For smaller teams that need the platform to do more of the heavy lifting, Profound's price point (which runs higher than Promptwatch and Peec) is hard to justify when you still need other tools to act on the data.
Relixir
Relixir is newer to this space and takes a different angle. Rather than leading with citation tracking depth, it leads with automated content generation to address citation gaps. The pitch is that you identify where you're missing and Relixir generates content to fill those gaps automatically.
The trade-off is that citation tracking is thinner. Relixir covers fewer models, provides less granular source-level data, and doesn't offer the crawler log visibility that Promptwatch has or the UI-scraping depth that Peec and Promptwatch share. If citation accuracy is your primary concern, Relixir isn't the strongest choice. If you want a more automated content pipeline and can accept shallower tracking data, it's worth evaluating.
Feature-by-feature comparison
| Feature | Peec AI | Promptwatch | Profound | Relixir |
|---|---|---|---|---|
| Data collection method | UI scraping | Real UI + crawler logs | API + UI (enterprise) | API-based |
| AI models tracked | 3 (Starter/Pro), more on Enterprise | 10 (all plans) | Multiple (enterprise-focused) | Limited |
| Citation URL tracking | Yes | Yes, with page-level detail | Yes | Basic |
| AI crawler logs | No | Yes (Professional+) | No | No |
| Sentiment tracking | Yes | Yes, by platform and prompt | Limited | No |
| Competitor benchmarking | Yes | Yes, with heatmaps | Yes, strong | Limited |
| Content gap analysis | No | Yes (higher tiers) | No | Yes |
| Content generation | No | Yes (higher tiers) | No | Yes (core feature) |
| Reddit/YouTube tracking | No | Yes | No | No |
| ChatGPT Shopping tracking | No | Yes | No | No |
| Pricing transparency | Yes ($100/mo Starter) | Yes ($99/mo Essential) | No (enterprise sales) | Limited |
| Free trial | Yes | Yes | Demo only | Limited |
Where citation accuracy breaks down across all four platforms
It's worth being honest about the limits that apply to every platform in this space, not just the weaker ones.
AI models are non-deterministic. The same prompt asked twice can return different citations. Every platform handles this by running prompts repeatedly and averaging results, but the sampling frequency varies and isn't always disclosed. A platform that runs each prompt once per day will show more variance than one that runs it multiple times.
Geography and language also affect citations. A prompt run from a US IP address may return different sources than the same prompt from a UK or German IP. Most platforms let you set location, but not all do, and results can differ meaningfully.
Conversation context matters too. A standalone prompt returns different citations than the same question asked mid-conversation. All four platforms test prompts in isolation, which is a reasonable approximation but not a perfect one.
None of these limitations make citation tracking useless. They mean you should treat citation data as directional signal rather than precise measurement, and you should weight platforms that are transparent about their methodology more heavily than those that aren't.
Which platform should you use?
The honest answer depends on what you're trying to do.
If you want the most accurate citation data across the widest range of AI models, Promptwatch is the strongest option. UI-based tracking across 10 models, crawler log cross-referencing, and page-level citation detail give you more confidence in the numbers and more context to act on them. The Essential plan at $99/month is a reasonable entry point, and the Professional plan at $249/month unlocks crawler logs, which is where the accuracy advantage really shows up.
If you're a smaller team that only cares about ChatGPT, Perplexity, and Google AI Overviews, Peec AI's Starter plan at $100/month is a clean, transparent option. The UI scraping methodology is solid, and the platform is genuinely easier to set up than Profound. The limitation is that you'll need to upgrade or switch if you want broader model coverage.
If you're an enterprise team that needs to present AI visibility data to a board or C-suite, Profound's reporting depth is hard to match. Just go in knowing you'll need separate tools or an agency to act on what you find.
If your primary bottleneck is content production rather than citation tracking, Relixir's automated generation angle might suit you. But don't expect Peec-level citation accuracy from it.
The question most teams aren't asking
Citation accuracy is important. But it's a means to an end, not the end itself. The teams getting the most out of AI visibility platforms in 2026 aren't the ones with the most accurate dashboards. They're the ones using citation data to identify specific content gaps and then closing those gaps quickly.
That's the distinction between a monitoring tool and an optimization tool. Monitoring tells you where you stand. Optimization tells you what to do about it and helps you do it.
Peec AI and Profound are monitoring tools. Good ones, but monitoring tools. Promptwatch is built around the full loop: find the gaps, generate content to fill them, track whether the new content gets cited. That's a different category of product, and for most marketing teams, it's the more useful one.
If you're evaluating platforms purely on citation accuracy, the gap between Peec AI and Promptwatch is smaller than their feature lists suggest. Both use real UI data. Both produce reliable directional signal. The bigger gap is in what you can do with the data once you have it.
A note on pricing and what you actually get
One thing that's genuinely frustrating about this category is how inconsistent pricing transparency is. Peec AI and Promptwatch both publish clear pricing. Profound doesn't, which makes comparison harder and usually signals a higher price point.
Here's a rough breakdown of what each platform costs at entry level:
| Platform | Entry price | Prompts included | AI models | Content tools |
|---|---|---|---|---|
| Peec AI | ~$100/mo | Limited (Starter) | 3 | None |
| Promptwatch Essential | $99/mo | 50 prompts | 9-10 | 5 articles/mo |
| Profound | Not public (enterprise) | Varies | Multiple | None |
| Relixir | Not public | Varies | Limited | Yes (core) |
The Promptwatch Essential plan at $99/month includes 50 prompts, 5 articles per month, and access to all 9-10 AI models. That's a better entry-level package than Peec's Starter for teams that want both tracking and content output in one place.
For teams that outgrow the Essential tier, Promptwatch's Professional plan at $249/month adds crawler logs, state and city-level tracking, and 15 articles per month. That's where the citation accuracy advantage becomes most concrete: you're not just seeing citations, you're seeing the full crawl-to-citation timeline.
Bottom line
Citation accuracy in 2026 comes down to data collection methodology first, model coverage second, and contextual depth third. On all three dimensions, Promptwatch leads. Peec AI is the strongest alternative for teams with narrower model requirements. Profound is the right call for enterprise reporting needs. Relixir is worth watching but isn't the accuracy leader yet.
Whatever platform you choose, treat the citation data as a starting point, not a final answer. The teams winning in AI search right now are the ones using that data to make faster content decisions, not the ones with the prettiest dashboards.